Chaque jour, nous vous offrons des logiciels sous licence GRATUITS que vous devriez autrement payer!

Giveaway of the day — PDF Text OCR Xtractor 3.2.2.20
L'offre gratuite du jour pour PDF Text OCR Xtractor 3.2.2.20 était valable le 17 avril 2023!

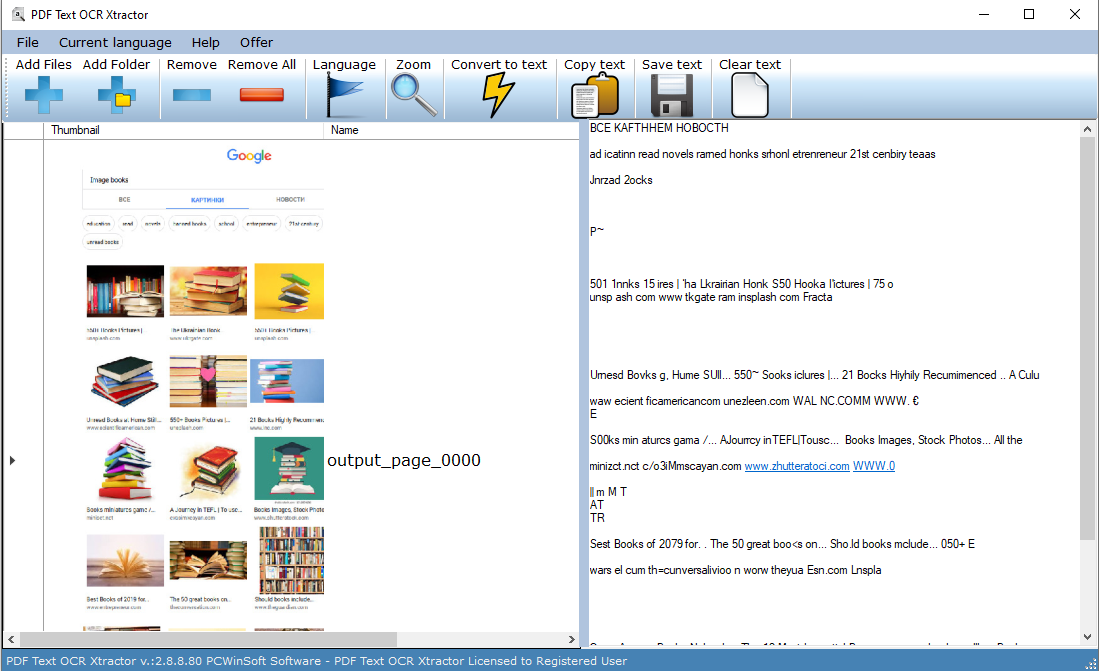
PDF Text OCR Xtractor est parfait pour extraire du texte de PDF et de toutes sortes de formats d'image populaires, tels que PNG, JPG, BMP et TIFF.
PDF Text OCR Xtractor utilise la technologie OCR Tesseract. Tesseract est peut-être le logiciel d'OCR le plus puissant et le plus avancé et voici pourquoi : Tout d'abord, un peu d'histoire. Il a été développé par HP en 1994, mais bientôt la société l'a publié sous licence Apache pour le développement open source. En 2006, Google a repris le projet et a parrainé des développeurs pour travailler sur Tesseract. Avance rapide maintenant et Tesseract est devenu le moteur OCR le plus puissant qui utilise le Deep Learning pour extraire des textes à partir d'images (BMP, PNG, JPEG, TIFF, etc.) et de fichiers PDF.
PDF Text OCR Xtractor prend en charge plus de 20 langues différentes et vous permet de définir des paramètres de traitement personnalisés pour les fichiers/images source, tels que le lissage et le réglage DPI, l'augmentation du contraste et d'autres astuces utiles, avant de les analyser.
PDF Text OCR Xtractor a une grande précision et obtiendra n'importe quelle image ou PDF que vous avez dans un texte consultable modifiable. La conversion de l'image en texte est rapide.
Caractéristiques principales:
1. Utilisation de la meilleure technologie OCR disponible.
2. Prise en charge de plus de 20 langues différentes.
3. Transformations d'images utiles pour améliorer la précision des documents difficiles.
Fonctionnalités supplémentaires:
1. L'interface utilisateur graphique du moteur Tesseract la moins chère que vous puissiez trouver !
2. Prise en charge de PDF et de tous les formats d'image courants tels que PNG, JPG, BMP.
Configuration minimale:
Windows 7/ 8.1/ 10/ 11 (x32/x64)
Éditeur:
PCWinSoftPage web:
https://www.pcwinsoft.com/pdf-to-text.aspTaille du fichier:
103 MB
Licence details:
lifetime
Prix:
$29.90
Commentaires sur PDF Text OCR Xtractor 3.2.2.20
Please add a comment explaining the reason behind your vote.